#MonadicMonday compilation: April

Episode 1: These/Ior monad
Welcome to #monadicmonday! Let’s start with a These/Ior monad.
These is a monad which expresses “inclusive-OR” relation:
These(A, B) = A + B + A * B.
These represents a simple idea: it can hold either value of type A, value of type B or both of them simultaneously.
It may be present in FP libraries under it’s literal name “These” (Haskell, TypeScript), or under “Ior” name (like in Scala’s cats package).
Take a look at the following function in TypeScript using These monad from fp-ts package by @GiulioCanti:
import { both, that, These, this_ } from 'fp-ts/lib/These';
// May warn if user is under 18, or panic if user has negative age
const greet = (name: string, age: number): These<Error, string> => {
if (age <= 0) {
return this_(new Error(`You age cannot be less than zero! You've entered: ${age}`));
}
const greeting = `Hello, ${name}!`;
if (age < 18) {
return both(new Error('You cannot use our service at that age!'), greeting);
}
return that(greeting);
};
Now let’s look at the examples. Note that we need to provide all possible “handlers” to fold function, so the monad could be reduced to a single value.
// Ex. 1: Alice is 14 years old:
const howIsAlice = greet('Alice', 14);
// Ex.2: Bob is hAx0r who tries to pen-test us:
const howIsBob = greet('Bob', -42);
// Ex. 3: Charlie is just a normie:
const howIsCharlie = greet('Charlie', 25);
Now let’s transform this code to a full example:
import { array } from 'fp-ts/lib/Array';
import { error, log, warn } from 'fp-ts/lib/Console';
import { io } from 'fp-ts/lib/IO';
array.sequence(io)([howIsAlice, howIsBob, howIsCharlie]
.map((person) => person.fold(
(err) => error(err.message),
(greeting) => log(greeting),
(err, greeting) => warn(err.message).chain(() => log(greeting)),
))).run();
Finally, let’s run our example!
You cannot use our service at that age!
Hello, Alice!
You age cannot be less than zero! You've entered: -42
Hello, Charlie!
Episode 2: rings
Welcome to the second episode of #monadicmonday! Today we’ll talk about algebraic data types, and more specifically – about semirings and rings.
First of all, let’s recap what a semiring is. Semiring is a set equipped with two binary operations, called “addition” and “multiplication”. The intuition that works here is such of natural numbers – you can define a semiring for Nat with addition as “+” and multiplication as “*”
A ring extends a semiring with an additional “inverse” operation (or, strictly speaking, ring implies that for each ‘a’ there exists ‘-a’). Rings and semirings must also have “zero” and “one” elements, and multiplication should distribute over addition.
The other important characteristic is that rings and semirings form a monoid under multiplication. Recap: monoid is defined using two operations:
combine :: A×A → A, which merges two monoids together,empty :: A, which defines an entity for “one”.
Let’s define a ring instance for Option (Maybe) data type. We can define it in several possible ways, and it depends on how we treat “None” value. I’ve called those instances “safe ring” and “strict ring”.
import { none, Option, some } from 'fp-ts/lib/Option';
import { getTupleRing, Ring } from 'fp-ts/lib/Ring';
const safeOptionRing: Ring<Option<number>> = {
zero: none,
one: some(1),
add: (x, y) => x.fold(y, (_x) => y.fold(x, (_y) => some(_x + _y))),
sub: (x, y) => x.fold(y, (_x) => y.fold(x, (_y) => some(_x - _y))),
mul: (x, y) => x.fold(y, (_x) => y.fold(x, (_y) => some(_x * _y))),
};
const strictOptionRing: Ring<Option<number>> = {
zero: none,
one: some(1),
add: (x, y) => x.fold(none, (_x) => y.fold(none, (_y) => some(_x + _y))),
sub: (x, y) => x.fold(none, (_x) => y.fold(none, (_y) => some(_x - _y))),
mul: (x, y) => x.fold(none, (_x) => y.fold(none, (_y) => some(_x * _y))),
};
Given a few different Option instances, we can observe different behavior of our rings:
const a: Option<number> = some(42);
const b: Option<number> = none;
const c: Option<number> = some(21);
// safe only:
const R1 = getTupleRing(safeOptionRing, safeOptionRing, safeOptionRing);
console.log(R1.add([a, b, c], [b, a, c])); // => [ some(42), some(42), some(42) ]
console.log(R1.add([a, b, c], R1.one)); // => [ some(43), some(1), some(22) ]
console.log(R1.sub([a, b, c], R1.zero)); // => [ some(42), none, some(21) ]
console.log(R1.mul([a, b, c], [a, b, c])); // => [ some(1764), none, some(441) ]
Strict rings:
// strict only:
const R2 = getTupleRing(strictOptionRing, strictOptionRing, strictOptionRing);
console.log(R2.add([a, b, c], [b, a, c])); // => [ none, none, some(42) ]
console.log(R2.add([a, b, c], R2.one)); // => [ some(43), none, some(22) ]
console.log(R2.sub([a, b, c], R2.zero)); // => [ none, none, none ]
console.log(R2.mul([a, b, c], [a, b, c])); // => [ some(1764), none, some(441) ]
Or we can mix&match a bit:
// mix&match:
const R3 = getTupleRing(strictOptionRing, safeOptionRing, strictOptionRing);
console.log(R3.add([a, b, c], [b, a, c])); // => [ none, some(42), some(42) ]
console.log(R3.add([a, b, c], R3.one)); // => [ some(43), some(1), some(22) ]
console.log(R3.sub([a, b, c], R3.zero)); // => [ none, none, none ]
console.log(R3.mul([a, b, c], [a, b, c])); // => [ some(1764), none, some(441) ]
If you can identify a structure as a (semi)ring, you can use its properties with confidence. For example:
- set of languages form a semiring with product as string concatenation and addition as set union;
-
boolean logic naturally forms a semiring: (Boolean, &&, , true, false).
Fun fact: semiring is sometimes called “rig”, because a riNg without Negative is just a “rig” ¯\_(ツ)_/¯
Semiring is sometimes defined as a monoid on + and a semigroup on *, i.e. 0 is mandatory but 1 is not. Then, Rig adds 1 only, Rng adds negation only, and Ring has both.
via λoλcat
I would like to give credit to Luka Jacobowitz for his awesome article “A Tale on Semirings”, which I recommend for reading: https://lukajcb.github.io/blog/functional/2018/11/02/a-tale-of-semirings.html
Episode 3: Recursion schemes
In this episode we’ll talk about quite complicated topic – recursion schemes. Hold tight, as the ride won’t be easy.
First of all, I would like to stress that I’m still grokking this topic, so if you spot a mistake, please ping me back!
Recursion schemes were popularized by a classical paper by Mejer, Fokkinga and Petterson called “Functional Programming with Bananas, Lenses, Envelopes and Barbed Wire”: https://eprints.eemcs.utwente.nl/7281/01/db-utwente-40501F46.pdf
Recursion schemes are powerful way to generalize various recursion algorithms and make them composable and easy to reason about. Importance of recursion schemes for FP is of the same scale as importance of design patterns for OOP. I would like to give credit to @importantshock for his magnificent work on blog “Adventures in Uncertainty”, which is the most thorough and detailed intro to recursion schemes I know: https://blog.sumtypeofway.com
There is a plethora of recursion schemes, to name a few:
- catamorphism tears down a structure layer by layer – you may think of it as a general
foldoperation; - anamorphism builds up a (recursive) structure layer by layer – you probably know it under
unfoldname; - para- and apomorphisms fold and unfold a structure while preserving the information about original strcuture. This is achieved by passing along the recursive calls not only the computed value itself, but also the original term;
- histo- and futumorphisms are dual morphisms which give you an access to previous (histo-) and future (futu-) results of the recursive computations. They are tremendously useful for solving dynamic programming problems, as we will see later;
- and many more: chrono-, dyna-, prepro-, postpro-, and so on, even the almighty zygohistomorphic prepromorphism, which has become a semi-joke in the functional programmer community.
As usual, I will illustrate my examples in Haskell-esque type definitions and TypeScript with fp-ts library for the solution itself. Let’s solve a problem: given a desired amount N, and an infinite supply S = { S1, S2, .. , Sm} of coins, how many ways can we make the change? BTW, this problem is described in great details in various tutorial blogs (like (link: https://www.geeksforgeeks.org/coin-change-dp-7/) geeksforgeeks.org/coin-change-dp…), so I won’t be describing the solution approach here. Instead I will show you how to implement it using a histomorphism.
Let’s recall histomorphism type:
histo :: Functor f => CVAlgebra f a -> Fix f -> a,
where
CVAlgebra f a = f (Cofree f a) -> a - a course-of-value algebra,
Cofree f a = Cofree { attribute :: a, hole :: f (Cofree f a) } - cofree comonad
and
Fix f = f (Fix f) - fixpoint of functor f
Well, I guess these parts require some additional explanation. Course-of-value algebra allows us to access the additional payload (attribute) of current recursive term, as well as fall deeper into it’s hole.
Cofree comonad is a good topic for another Monadic Monday, so today I will just say that it’s a way to “mark” a recursive term with an additional marker of type a.
A Fix is an Y-combinator (fixpoint combinator) on the type-level, so it just represents an infinite sequence of type application:
type Fix t = t (t (t (t (t ...))))
For example, a singly-linked list can be described like so:
type List a = Fix (L a)
data L a b = Nil | Cons a b
You can think about list as a math isomorphism https://twitter.com/xgrommx/status/880560506385252353 1) Understanding via abstraction (build a new abstraction) 2) Math isomorphisms 3) Category theory (Category of F-algebras)
via Denis Stoyanov
To begin solving our coin change problem, let’s define our auxillary types in TypeScript. We will need:
Fixtype;Nattype to represent Peano numbers;Cofreetype for our comonad;- instance
NatCfor Cofree<Nat, a>; CVAlgebra;- and
matchfor pattern-matching:
import { Lazy } from 'fp-ts/lib/function';
import { HKT, Type, URIS } from 'fp-ts/lib/HKT';
export class Fix<F> {
constructor(public readonly value: HKT<F, Fix<F>>) { }
}
export function fix<F>(value: HKT<F, Fix<F>>): Fix<F> {
return new Fix(value);
}
export function unfix<F>(term: Fix<F>): HKT<F, Fix<F>> {
return term.value;
}
export class Cofree<F, A> {
constructor(readonly attribute: A, readonly hole: HKT<F, Cofree<F, A>>) { }
}
export const cofree = <F, A>(a: A, h: HKT<F, Cofree<F, A>>) => new Cofree(a, h);
export const attribute = <F, A>(c: Cofree<F, A>): A => c.attribute;
export function hole<F extends URIS, A>(c: Cofree<F, A>): Type<F, Cofree<F, A>>;
export function hole<F, A>(c: Cofree<F, A>): HKT<F, Cofree<F, A>> { return c.hole; }
export type Algebra<F, A> = (fa: HKT<F, A>) => A;
export type CVAlgebra<F, A> = (fa: HKT<F, Cofree<F, A>>) => A;
export const match = <T extends string>(toMatch: T) => <B>(ops: Record<T, Lazy<B>>) => ops[toMatch]();
Definition of Nat type requires some boilerplate in TypeScript, compared to terse Haskell counterpart:
data Nat a = Zero | Succ a
deriving Functor
import { Functor1 } from 'fp-ts/lib/Functor';
import { Fix, fix } from './Fix';
declare module 'fp-ts/lib/HKT' {
interface URI2HKT<A> {
Nat: NatF<A>;
}
}
export const URI = 'Nat';
export type URI = typeof URI;
export class Zero<A> {
static value = new Zero<any>();
public value: never;
readonly _tag: 'Zero' = 'Zero';
readonly '_A': A;
readonly '_URI': URI;
private constructor() { }
map<B>(_f: (a: A) => B): NatF<B> {
return this as any;
}
}
export class Succ<A> {
readonly _tag: 'Succ' = 'Succ';
readonly '_A': A;
readonly '_URI': URI;
constructor(public value: A) { }
map<B>(f: (a: A) => B): NatF<B> {
return new Succ(f(this.value));
}
}
export type NatF<A> = Zero<A> | Succ<A>;
export type Nat = Fix<URI>;
export const zero = fix(Zero.value);
export const succ = (n: Nat): Nat => fix(new Succ(n));
export const functorNat: Functor1<URI> = {
URI,
map<A, B>(nat: NatF<A>, f: (a: A) => B): NatF<B> {
return nat.map(f);
},
};
The implementation of histo itself is identical to it’s Haskell original from https://blog.sumtypeofway.com/recursion-schemes-part-iv-time-is-of-the-essence/:
export function histo<F extends URIS>(F: Functor1<F>): <A>(h: (fa: Type<F, Cofree<F, A>>) => A) => (term: Fix<F>) => A;
export function histo<F>(F: Functor<F>): <A>(h: CVAlgebra<F, A>) => (term: Fix<F>) => A {
return <A>(h: CVAlgebra<F, A>) => {
return function self(term): A {
const worker = (t: Fix<F>): Cofree<F, A> => {
const calc = F.map(unfix(t), worker);
return cofree(h(calc), calc);
};
return attribute(worker(term));
};
};
}
To begin with the solution, we’ll need to define two helper which convert a common JavaScript number into Nat and vice versa:
// NatC – cofree wrapper around our target solution type - list of "ways of change",
// i.e. all possible combinations of change for the given amount:
export type NatC = Cofree<URI, number[][]>;
// Convert plain JavaScript `number` into Peano number:
const expand = (amt: number): Nat => amt === 0 ? zero : succ(expand(amt - 1));
// Convert Peano number back to `number`:
const compress = (n: NatF<NatC>): number => match(n._tag)({
Zero: constant(0),
Succ: () => 1 + compress(hole(n.value)),
});
Finally, let’s define change function, which differs from the one @importantshock described in his article. My implementation stores not just a number of ways given amount can be exchanged – this information is insufficient for the correct solution. Instead, I store the exact solutions for each amount. This gives me an additional bonus: I can print not only a number of ways, but the ways themselves! That’s why my NatC instance for Cofree was holding not just a number, but an array of number arrays.
const lookup = <A>(cache: Cofree<URI, A>, n: number): A =>
n === 0 ? attribute(cache) : lookup(hole(cache).value, n - 1);
const COINS = [1, 5, 10, 25, 50];
const change = (amt: number): number[][] => {
const go = (curr: NatF<NatC>) => match(curr._tag)({
Zero: constant([[]]),
Succ: () => {
const given: number = compress(curr);
const validCoins = COINS.filter((c) => c <= given);
// This is what differs: we store not only the sum of ways, but the exact solution itself:
const remaining: Array<[number, number]> = validCoins.map((c) => ([c, given - c]));
const { right: zeroes, left: toProcess } = partition(remaining, (a) => a[1] === 0);
const results: number[][][] = toProcess.map(
([coin, remainder]) => lookup(curr.value, given - 1 - remainder).reduce<number[][]>(
(arr, coins) => (coins.every((c) => c <= coin) && arr.push([coin, ...coins]), arr),
[],
),
);
return zeroes.map(([c]) => [c]).concat(...results);
},
});
return histo(functorNat)(go)(expand(amt));
};
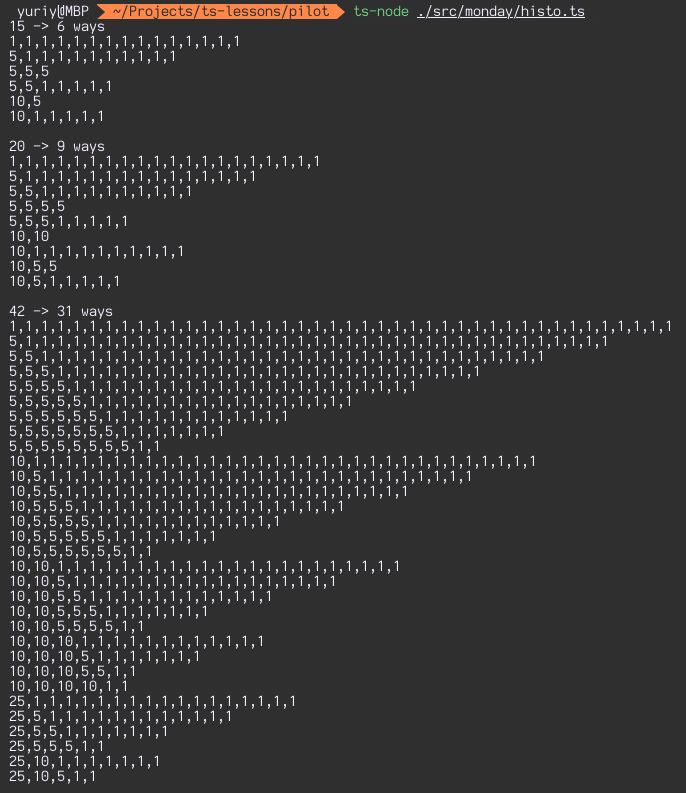
And here’s the result of running change for amounts of 15, 20 and 42 cents. We get not only valid sum, but all possible ways of change, too:
Episode 4: Either and co.
In this episode we’ll talk about specialized variants of Either monad.
The first one I’d like to show is awesome RemoteData from @devexperts: https://github.com/devex-web-frontend/remote-data-ts
This monad encapsulates four states of network request:
- request not started yet;
- request is running;
- request failed;
- request succeeded.
This allows a developer to always handle erroneous and pending states of a network request – which, obviously, is a common thing among web devs.
Using RemoteData, I usually build my Redux store in the following way:
- any data that is coming from the net is wrapped in RD;
- in redux-saga I
yieldpending as a first operation, and then – either failure or success when the request is finished; - in reducers I just pass RD as is without any folding;
- in my components I fold RD as late as possible – usually when I need to render it’s data as a JSX.
It looks something like this:
Saga:
function* getDataSaga() {
yield put({ type: 'GET_DATA_START', payload: pending });
const result: RemoteData<Error, Data> = yield call(API().getData());
yield put({ type: 'GET_DATA_FINISH', payload: result });
}
Reducer:
const getDataReducer =
(state = initial, { type, payload }: AnyActionWithPayload<Data>) => {
switch (type) {
case 'GET_DATA_START':
case 'GET_DATA_FINISH': {
return payload;
}
default: {
return state;
}
}
};
Component
const mapDispatchToProps = (dispatch: Dispatch<ApplicationState>) => ({
load: dispatch({ type: 'GET_DATA_INIT' }),
});
const MyComponent: React.FunctionComponent<MyComponentProps> = ({ dataRD, load }) => {
const doLoad = () => {
load();
};
return (
<>
{dataRD.foldL(
() => <Button onClick={doLoad}>Load!</Button>,
() => <CircularProgress variant='indeterminate' />,
(error) => <Typography variant='h1'>{error.message}</Typography>,
(data) => <User model={data.user} />,
)}
</>
);
}
One positive consequence of RemoteData lies outside of code. My co-developers are “forced” to think about pendings (=loading) and failures (=errors), so they ask designers to provide explanation of system’s behavior in all situation, so system can never be in inconsistent state.
The other useful ADT I would like to expose is Validation. It looks and behaves similar to Either, with one defference: it’s not a monad, but an applicative functor. I recommend reading great article by @GiulioCanti: https://dev.to/gcanti/getting-started-with-fp-ts-either-vs-validation-5eja
Another useful monad, These, was described in the first episode: https://twitter.com/YuriyBogomolov/status/1112712151062458370. It’s not an extension of Either like RemoteData, but carries similar to Either business semantics.
Conclusion
These were the topics covered during April’s Monadic Mondays. Please let me know what do you think of it! I would be happy to get your feedback, so please ping me back at @ybogomolov in Telegram, @YuriyBogomolov in Twitter or via yuriy.bogomolov@gmail.com.